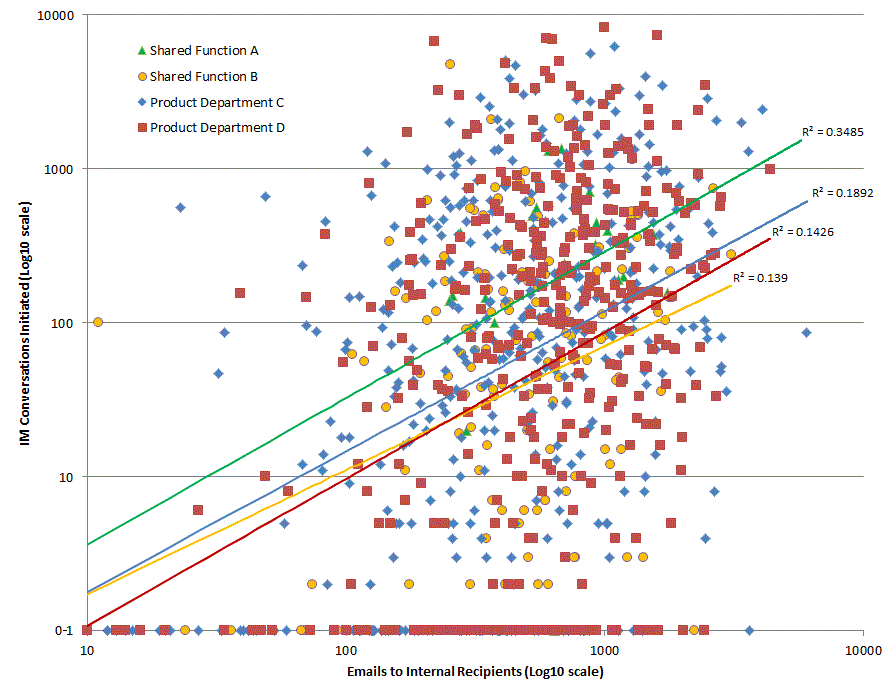
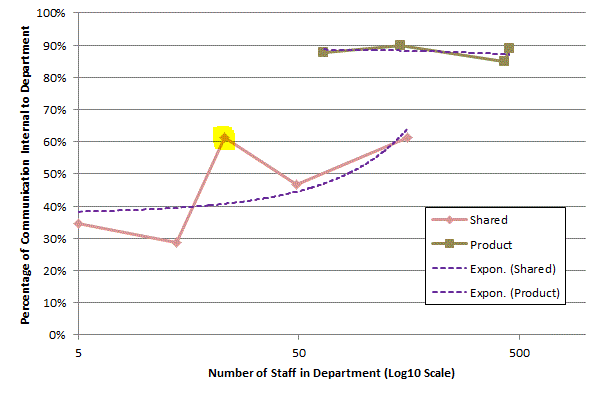
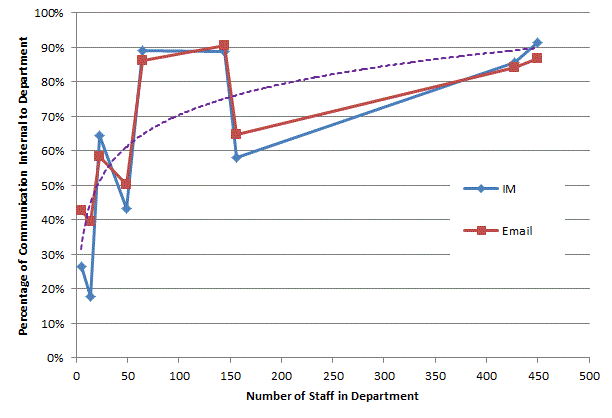
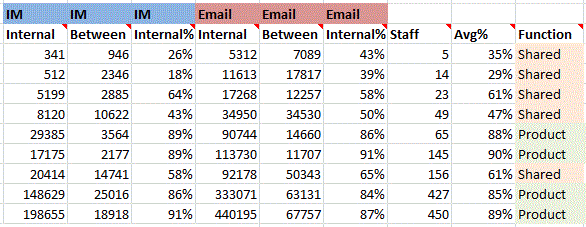
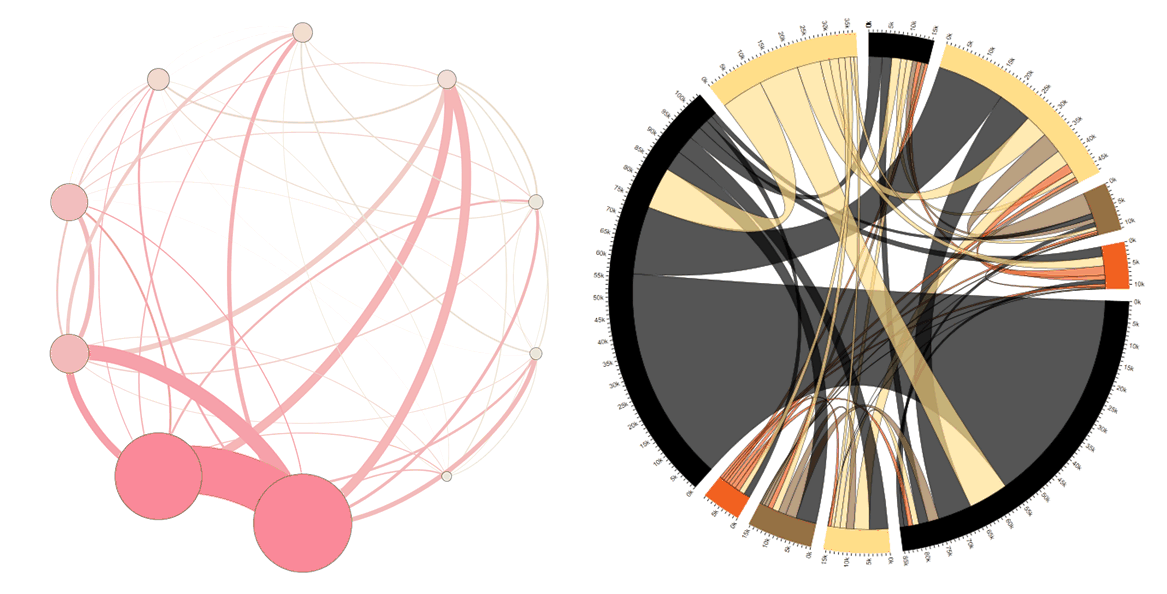
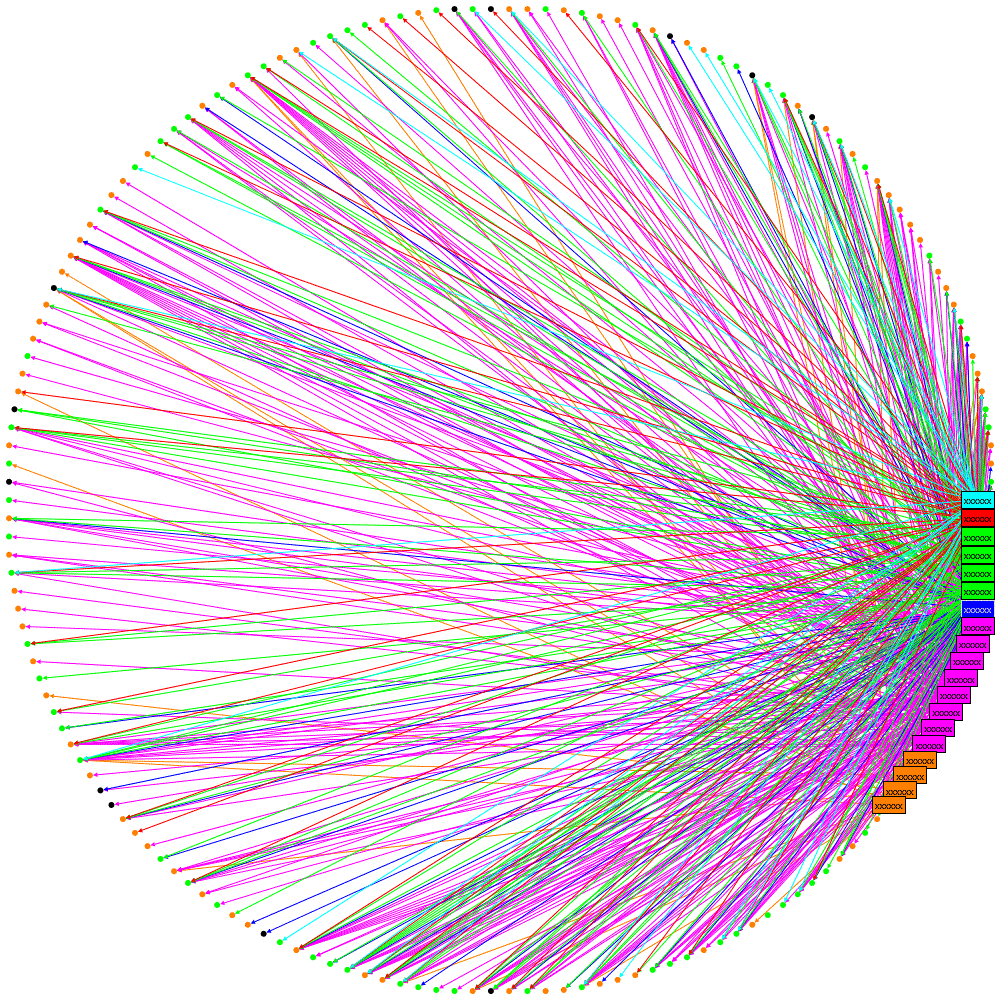
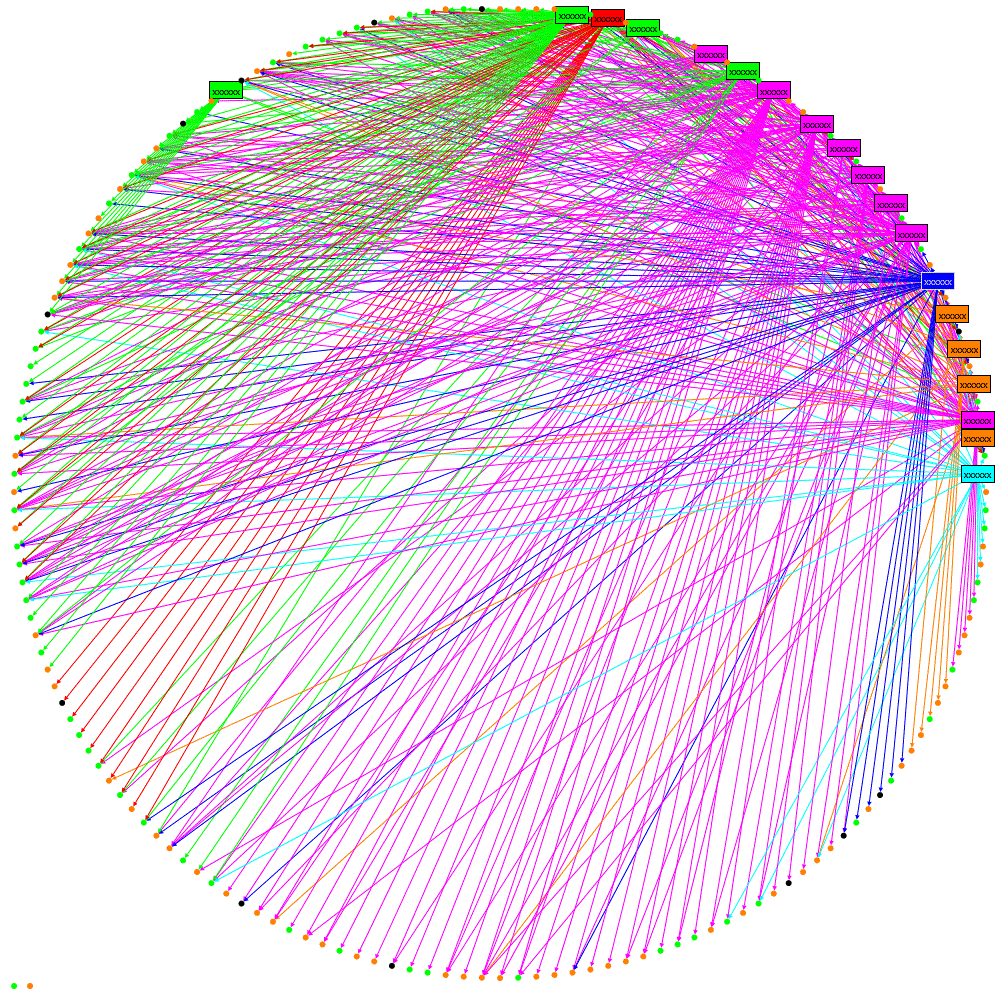
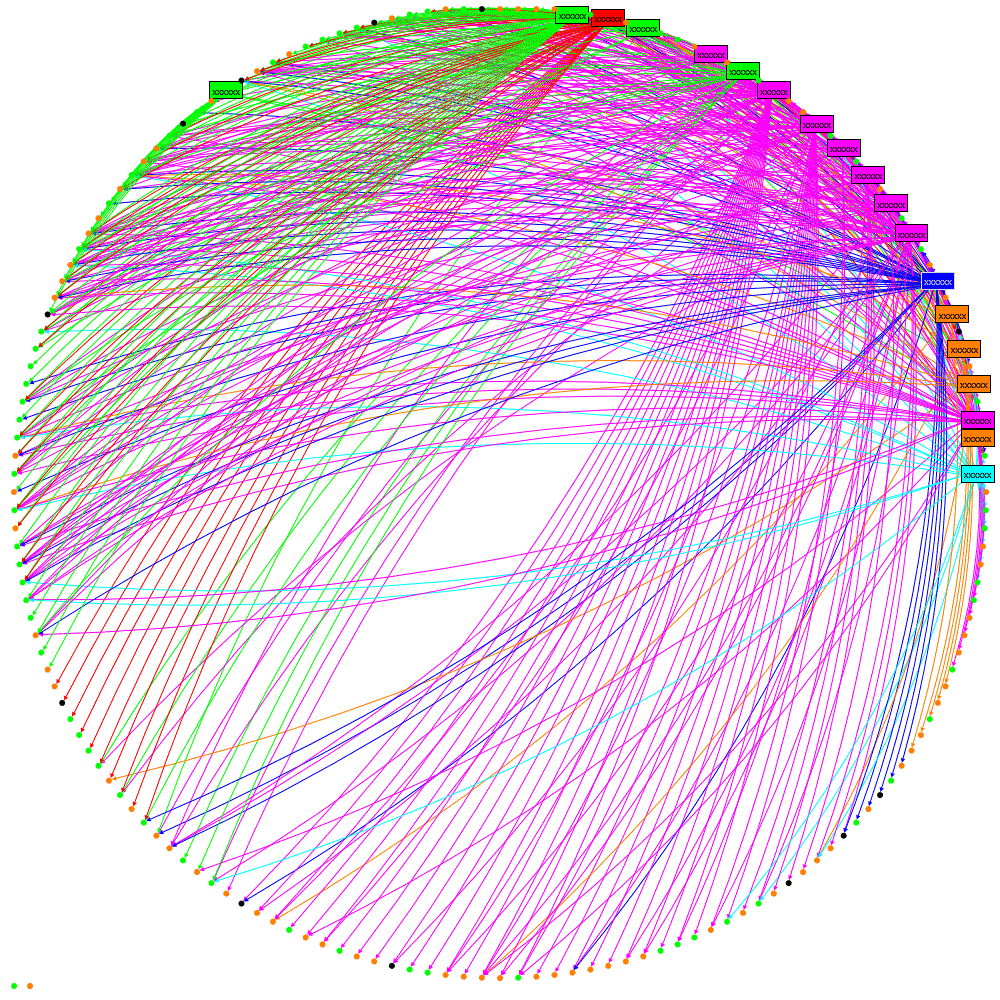
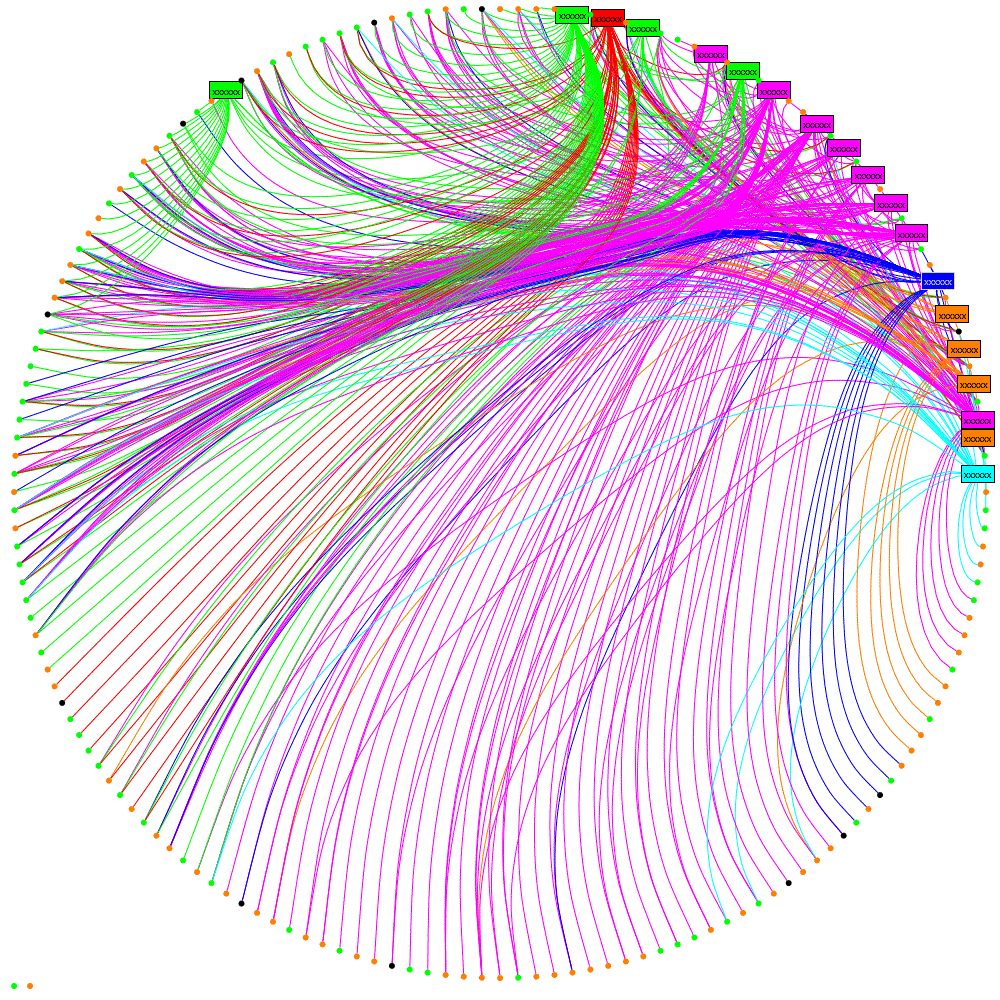
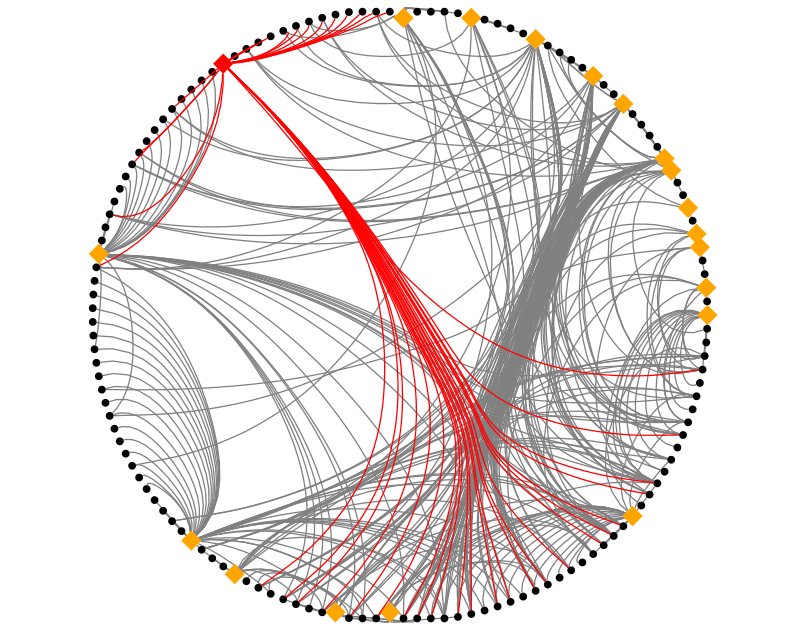
Making the most of available data within an organisation needs to balance the effort of obtaining and analysing the information against the value derived from that information. I’ve been looking to see if IM data is worth collecting when an organisation has already collected email data. The following graphic shows social networks based on Email, IM and then combined data, each colour represents a department in the organisation being studied:

Visually the following can be observed:
- Email is much more heavily used than IM and gives a more complete picture of the network
- The result of combining Email and IM shows that the email structure dominates but, as one can see, the department coloured magenta (•) has moved from neighbouring the red (•) department to neighbouring the green (•) department. At this time I don’t have an explanation as to why such a dramatic change is seen but I will be investigating.
But what do the numbers look like? The following graph metrics were calculated using Gephi:
| IM | Combined | ||
| Average Degree |
71.672 |
15.682 |
74.263 |
| Avg. Weighted Degree |
1722.546 |
705.802 |
2331.18 |
| Network Diameter |
4 |
7 |
4 |
| Graph Density |
0.054 |
0.014 |
0.056 |
| Modularity |
0.661 |
0.689 |
0.667 |
| Avg. Clustering Coef. |
0.395 |
0.261 |
0.391 |
| Avg. Path Length |
2.281 |
3.115 |
2.252 |
Adding in the IM data has increased Average Degree from 71.6 to 74.2 and Graph Density from 0.054 to 0.056; this shows that it has identified relationships that email did not and, therefore, does enhance the pure email graph.
If using the graph to identify the strength of relationships or influence the next question is what weight to assign to IMs compared to email? My initial thought was that an IM contains much less than an email so would be worth an order of one-tenth of an email. However measuring the average degree of IMs (16) it seems that people are more reserved in who they communicate with using IMs and, presumably, have a closer relationship. Therefore I have equated one IM message with one email message.
 Follow
Follow