When entering outsourcing arrangements many organisations like to bring in the role of “Relationship Manger” which is supposed to act as the interface, or at least an initial broker, between the two organisations. Each party tends to have these roles and the amount of informal communication that does not travel via these roles varies depending on the levels of trust and formality. The question is how many people should be in these roles and between which groups in the two organisations should they be placed?
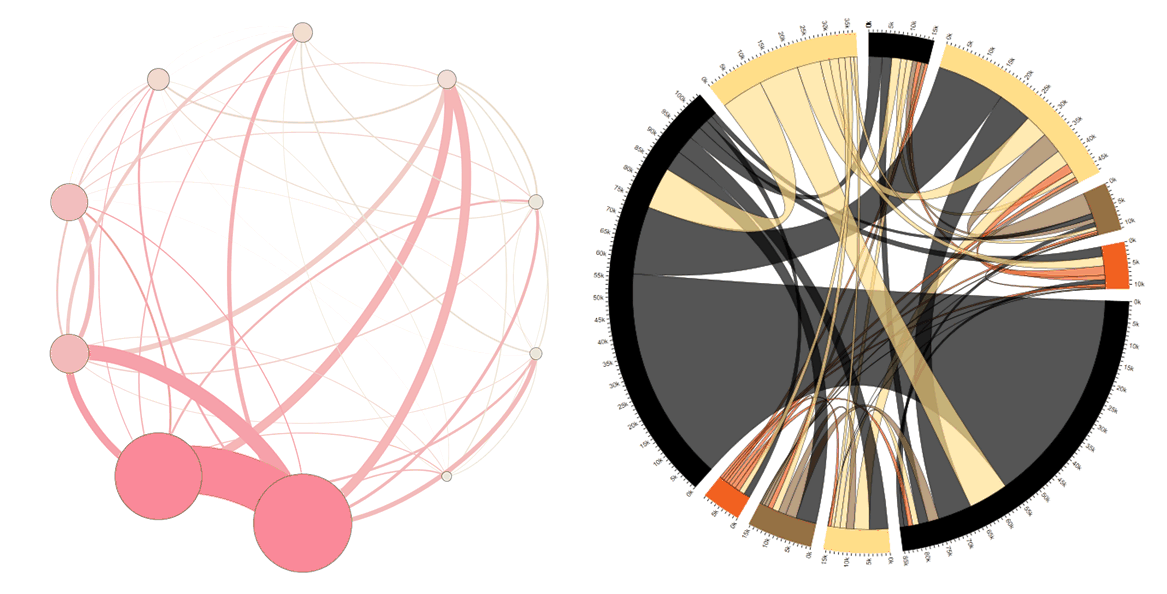
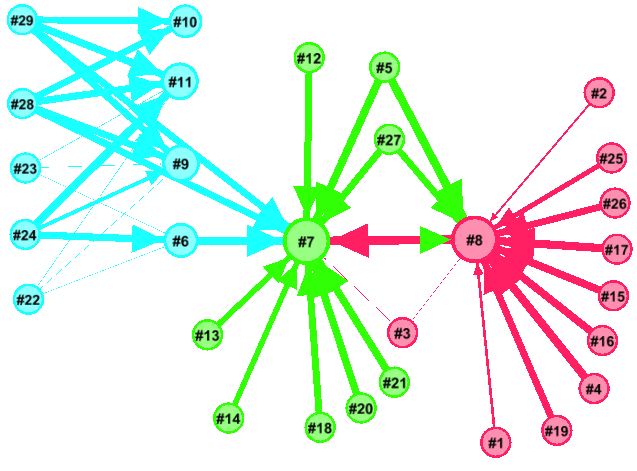
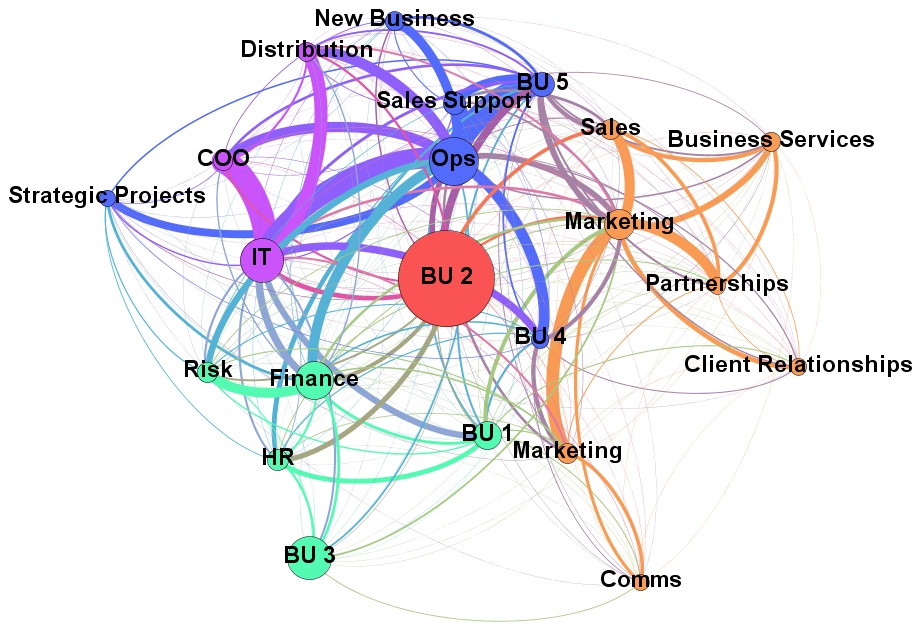
Looking at the original organisation, prior to outsourcing, some simple SNA tools can help: by measuring the communication between the two groups (retained and outsource target) it can be seen who the key people are bridging the groups and the volume of that communication. Using a tool, like Gephi, and running a layout such as Fruchterman-Reingold this can be visualised as shown below:

Note in the centre there are some individuals with strong ties between the two groups, this would be a prime place to consider placing relationship managers. There are also another couple of interesting observations: (1) there are a lot of less strong relationships between individual in the two groups which, taken individually, might not seem significant but when added up are significant and must be considered; (2) some individuals appear to be in the wrong group (e.g. the red dots amongst the green dots) and their allocation to the ‘retained’ or ‘outsource’ group should be reconsidered.
 Follow
Follow