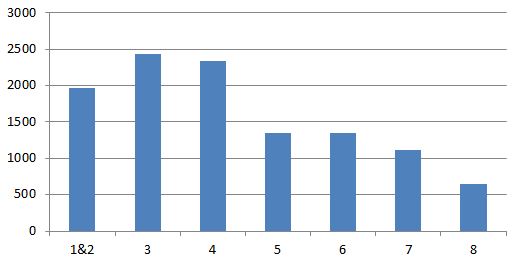
If you want to perform analysis comparing sub-sets of a graph derived from your email logs you will need to bring in some additional data, for example department. You might be lucky in that the organisations addressing scheme provides some clues e.g. ‘[email protected]’ or ‘[email protected]’ but if not you will have to find another source. Now you might have an efficient HR department who could provide an extract of employees with department, role and any other data they don’t mind you having. Or they might not be so helpful. If HR won’t help there are some other sources: the directory service (e.g. Microsoft Active Directory) or maybe an intranet site that acts as a phonebook and/or organisational chart. Which one you select will depend on content and accuracy. In my case the intranet site provided both the most accurate and richest source of data. Each intranet is going to be different so maybe the following is not going to work for yours but I hope the approach provides some inspiration.
The intranet I have worked with is composed of two page types:
- A page describing the employee with phone numbers, job role, location, department and also some free-text fields allowing people to input experience, skills, what they work on and languages spoken.
- A Hierarchy page: given an employee it displays their manager and direct reports.
Luckily each page type could be bought up by knowing the employee and manager ID and constructing a fairly simple url.
I thought it would be useful to understand where an employee sits in the overall structure so I wrote a program to traverse the directory top-down. Given a known starting point (the ID of the most senior employee and their manager, effectively blank) the algorithm worked like this:
- Find all the direct reports of the current employee
- Recursively call step 1 for each direct report (if any) and keep a count of how many there are
- Get the directory information for the current employee
- Store the directory information and the count of direct reports plus any other derived information (e.g. the employee’s level in the hierarchy and a list of all the managers above them)
Now unfortunately this does not find all the employees we have email records for; this turned out to be because the intranet directory is incomplete so as a second exercise:
- Find all the employees for which there is an email record but no directory entry recorded from the first phase
- Query the intranet directory by email address (fortunately this was a feature of the one I was using)
- Store the directory information
This second step could be used to populate the whole list but it does not provide such rich hierarchical information.
The directory information is best retained in its own table. This is because it changes over time and should be obtained periodically (e.g. monthly). However a refresh of the directory data SHOULD NOT overwrite, instead add a field that contains the date the data was fetched. This makes it possible to use directory data that corresponds to the period of data being analysed or to still derive a tie between people: if A used to manage B, even if they no longer do.
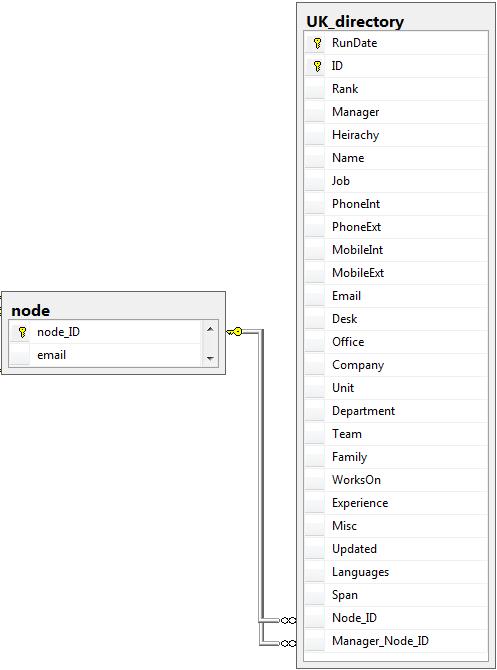
Example directory table. Note: RunDate is the date the directory was traversed (there will be multiple runs in 1 table); ID and manager are internal IDs for the intranet directory; rank is the position in the hierarchy (0 highest); Span is the number of direct reports.
 Follow
Follow