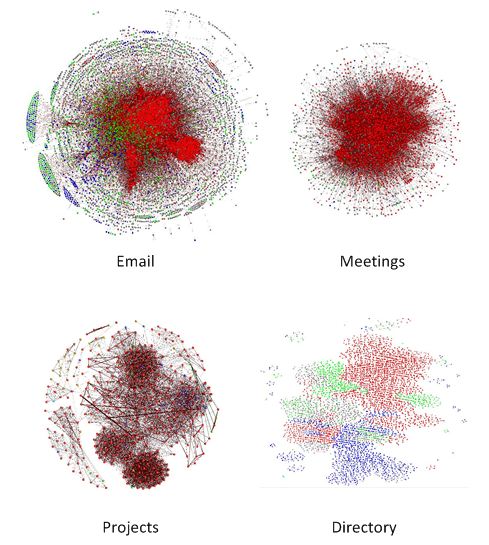
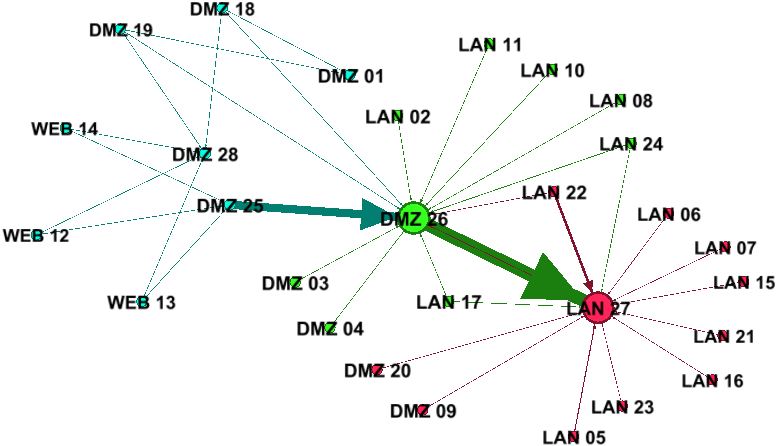
The next data source you may have in your organisation also comes from Microsoft Exchange Server. If you use Exchange Server to book meeting rooms then this can be mined. As always what can be accessed will depend on your organisations privacy policies. In the organisation I describe here I have access to the calendars for well over half of the meeting rooms using my standard authentication credentials because I am allowed to book meetings in these rooms. Through the room calendar I can also see when other people have booked meetings; it’s not possible to see the meeting subject but it is possible to see a list of attendees. Unlike email I have accessed the meeting room calendars through the Exchange Server API; this is described by a number of others so I won’t reproduce it here, search for ‘Microsoft.Exchange.WebServices’ and ‘GetRoomLists’.
Meetings differ from email in that they are a many-to-many event rather than on-to-many. There will be a meeting organiser but this is often a PA so I do not give any special meaning to them. Just as with email I prefer to load data into a relational database first, the table structure is shown, below.
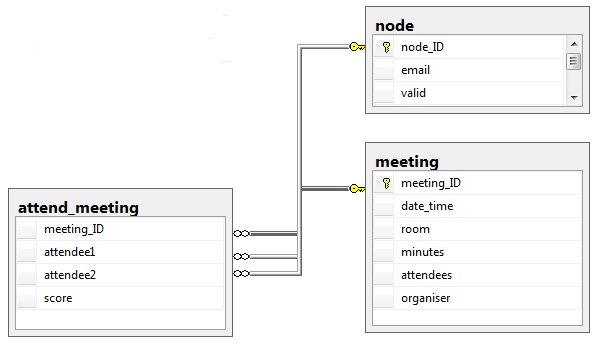
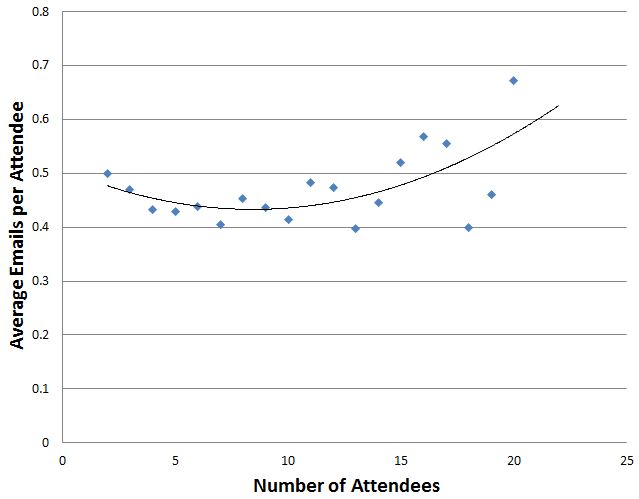
You’ll notice that the table attend_meeting has a field ‘score’; this table has an entry for every pair of attendees at the meeting but how to give each pair a score? Starting with the premise that a two-person meeting means each person is receiving the full attention of the other I need to find a way to reduce this score as the number of attendees increased and I found the following seemed to be a good fit:
score = minutes / ( n * ( n -1 ) / 2 ) where n = number of attendees
The table below shows the scores for a 60 minute meeting
Attendees, x=(n * (n -1)) / 2, minutes/x
2 1 60
3 3 20
4 6 10
5 10 6
6 15 4
7 21 3
8 28 2
9 36 2
10 45 1
After 10 attendees the score is always set to 1
I found an interesting discussion of Dunbar’s Number in ‘Connected: The Amazing Power of Social Networks’ by Nicholas Christakis which suggests the maximum effective meeting size is 3.8 (OK let’s call it 4) which seems to support the fairly rapid degradation of the importance of a meeting (as a social network building tool) when the number of attendees increases. If you check out the book at Amazon http://www.amazon.co.uk/dp/0007303602/ and look at the preview you’ll see the discussion on page 249.
 Follow
Follow