Showing someone a graph of where they fit into an organisation along with over 2000 colleagues is simply not practical, not only can’t it all be fitted on a screen at a meaningful level but it’s just going to be a mess of edges (connections). I previously described loading SNA data first into a relational database and then into Neo4j. The structure I have built in Neo4j is quite simple: a node (person) has a number of attributes including email address and languages which is a list of languages a person speaks (people provide this information to the corporate directory). The edges in Neo4j have a single attribute, score, which attempts to represent the relative strength of the relationship between two people (nodes). The score is derived from a number of data sources I have previously described.
So here’s the scenario I’m looking at: let’s say you need to find someone who speaks German; the corporate directory can be searched on a number of attributes including language but what if you don’t know any of the people who speak German and you don’t really want to approach people you don’t know. Well this is where your friends of friends might be able to help but how do you know which of you friends may know one of the people who speak German. Well this is perfect territory for graph databases.
To query Neo4j firstly I’ve enabled auto-indexing for the email and languages attributes (along with others); this is done by editing the neo4j.properties file in the conf folder:

Then, using the Neo4j’s cypher query language execute the following (I’m rather proud of this Cypher query but I’m sure a Cypher expert might be able to put me right):
START
n=node(*), m=node:node_auto_index(email = ‘[email protected]’)
MATCH
p = allShortestPaths( (m)<-[r*..6]->(n) )
WHERE
n.languages =~ ‘(?i).*german.*’
RETURN DISTINCT
length(p) AS len,
EXTRACT( n IN NODES(p):n.email) AS email,
EXTRACT( r IN RELATIONSHIPS(p):r.score) AS score
ORDER BY
length(p)
Let’s take that apart:
- START: defines two sets of nodes: n is all or any node, m uses the query to locate the node that matches the email address of the user making the query
- MATCH: the allShortestPaths is a built-in function that does exactly what it says, its argument restricts this to a maximum of six hops and between the two sets identified in the START clause; it returns a list of paths, referred to as p. (A path contains the both nodes and edges, e.g. you get Node1–Edge1->Node2–Edge2->Node3). Every path will connect a node n (the German speaker) to node m (the user making the query) and include up to 4 intermediary nodes.
- WHERE: this reduces the size of set n (remember this is node(*) ) to only those that have a language attribute matching the supplied regular expression (the fiddly bits just means ignore the case)
- RETURN: there will be three things returned:
- the length of the path,
- a list of all the nodes in the path
- the ‘score’ values between each pair of nodes
- ORDER BY: shortest paths are best (usually, more of that next), so the ordering is by the path length
Now shortest paths are best, right? Well maybe but from the work I’ve previously described there is a score for every relationship (edge), is a short path with low scores better than a long path with high scores? Well I don’t know and I’d love to hear from anyone who’s read a paper on the subject or has any views. The following illustrates this, the capital letters represent a node (person) and the number in brackets is the score of the relationship between the two nodes. A is the user making the query and X speaks German, there are the following paths:
Path 1: A–(350)–B–(193)–X
Path 2: A–(5)–C–(9)–X
Path 3: A–(150)–D–(210)–E–(105)–X
Clearly the first is pretty good: the path is short and the relationships are relatively strong. But what about the next one, the path is short but A does not know C that well and, likewise, C does not know X well; it may be better to go via D and E, although the path is longer everyone on it probably has a strong relationship.
Having experimented empirically I found a good result is obtained by ranking the paths based on the lowest relationship score in the path (think of this as the ‘weakest link’), the above three paths are ordered thus (I have highlighted the ‘weakest link’ in each):
Path 1: A–(350)–B–(193)–X
Path 3: A–(150)–D–(210)–E–(105)–X
Path 2: A–(5)–C–(9)–X
Results with this ranking appear to work very well; in general shortest paths tend to feature and longer paths with high scores are rarer because, of course, it only takes one weak link to demote it in the rankings.
The ranked paths can be presented to the user but there is often a lot of redundancy, it could be that Path 3 is repeated but going through node F instead of E. Therefore I’ve found it better to turn the list of paths back into a graph. I’ve used a visualisation component from the excellent NodeXL library to do this. I’ve also limited the number of paths displayed as too many produce a somewhat unreadable result; this is why ranking the paths was important, we want to display the best ones if we can’t display them all.
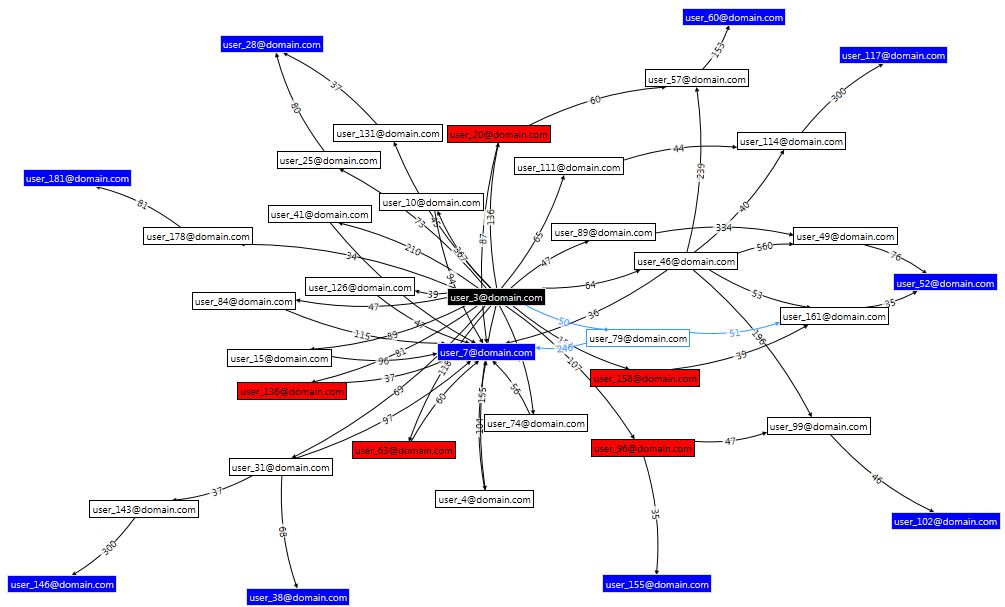
The black node in the centre is the user making the query; blue nodes are people who can speak German; white nodes are intermediaries. The red nodes represent people who have left the organisation, they aren’t really that useful here I just haven’t got round to adding an option to filter them out. Each relationship (line) is labelled with the score (strength).
 Follow
Follow
Pingback: An individual’s view of their network | gimeno.co.uk
Pingback: Mapping the Graph of Retweets | Robert Gimeno's Adventures in Data Science