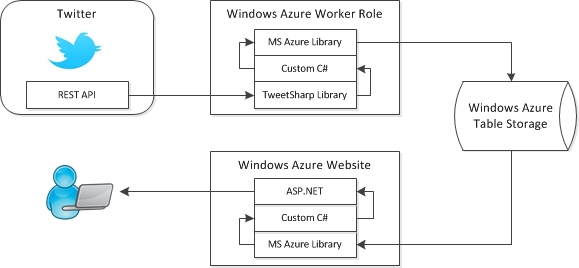
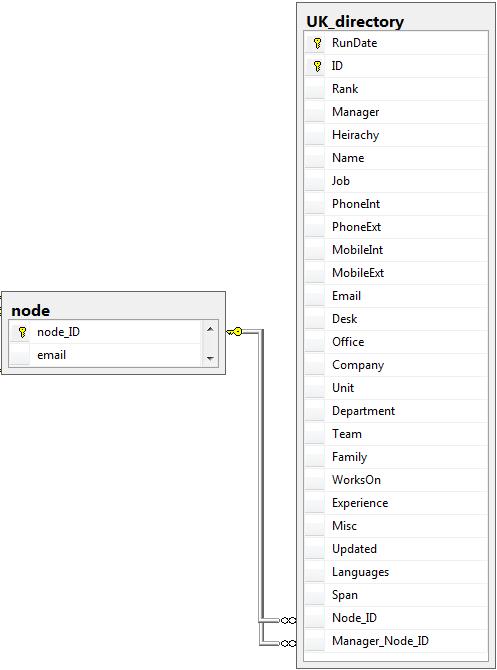
An interseting couple of days.
Google are targeting enterprises as a PaaS provider. Their view is Digital Natives will bring consumer technologies into the workplace and concentrate on systems of collaboration rather than systems of record . They put a lot of value in the Gartner Nexus of Forces.
Performance Management of Cloud Platforms (PaaS): with elastic computing sloppy development of inefficient code can be masked by infrastructure but at what cost? Application Performance Monitoring may be more important, than in on-prem, to help stop money leaks.
The panel discussion of Big Data Skills started with a great quote: “do you have a [Big Data] Problem or is it a Big [Data Problem]?”, well I found it amusing. The discussion concluded that:
- Many organisations are struggling to get Big Data out of R&D
- We need to be careful that it does not become over-intrusive in people’s lives
As we know there is rarely anything genuinely new: I met the guys from elasticsearch who explained it uses Lucene (as does Neo4j) to index text and that this was something called an inverted index. Well that bought back a few memories from the early 90s when I worked for Dataware Technologies integrating BRS into customer solutions.
The Open Data Institute promote the use of government data and offer help (not financial) to start-ups who want to take that data and add value to it.
Talend echoed sentiment from last week’s BDA conference: why Extract – Transform – Load when you can Extract – Load – Transform using Hadoop.
The Cloud Security Alliance called for more transparency and honesty which should apply to corporations as well as governments. It’s something Enterprise Architects need to consider when they examine proposals that will impact individuals’ anonymity.
The question of whether recent revelations about PRISM will see people move away from Facebook was raise during a panel discussing protection of sensitive data in the cloud. I suspect not but time will tell.
Digital Innovation Group reinforced the message about the importance of context and trying to understand the language of peoples social media output. You need to be able to deal with slang and differentiate between not agreeing with an opinion versus that being their opinion.
 Follow
Follow