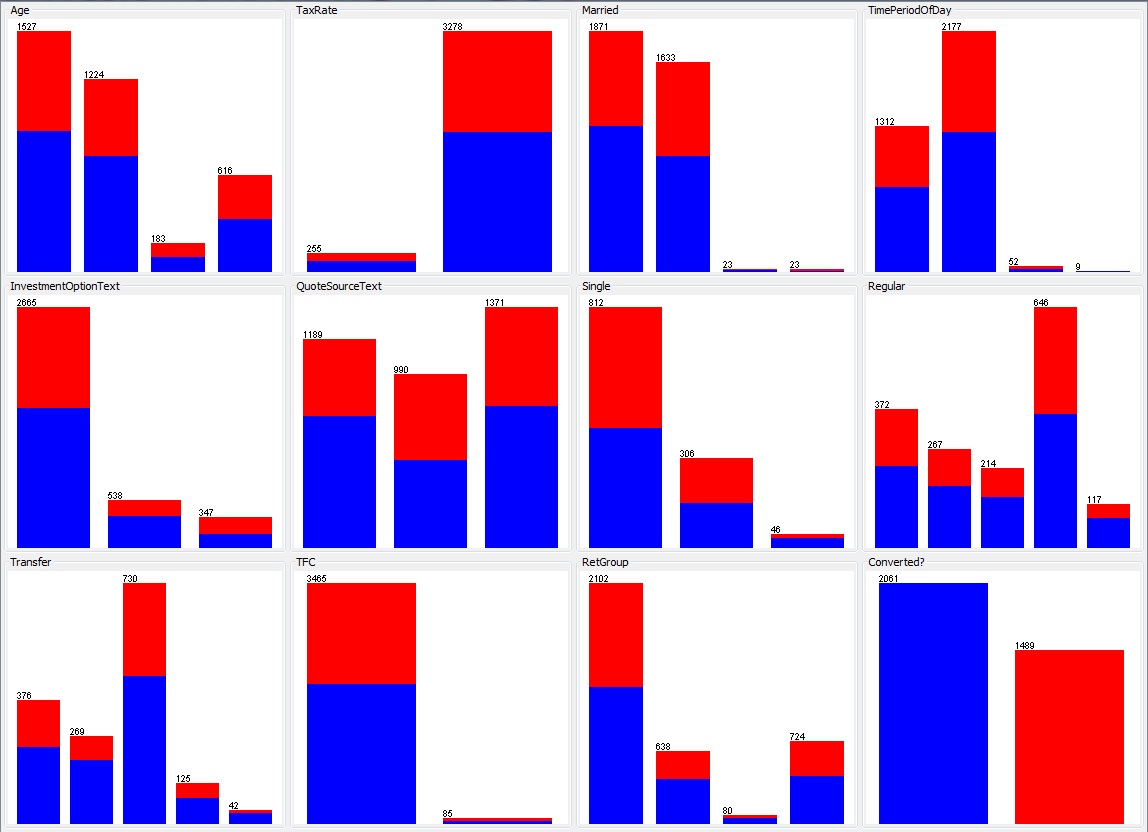
I previously described a dataset that was stubbornly refusing to yield any predictability. Using a larger set of the same data I realised that rather than trying to predict an individual opportunity to sell what was actually of interest was is a particular lead likely to become a customer (most people don’t buy multiple products of this type and there is often a number of interactions with each customer before a sale). By focussing on customer it became clear there were some noticeable distributions amongst the parameters. The dataset was very nicely split 50/50 between successful and non-successful opportunities and the best predictors were able to correctly classify almost 70% of cases. The most accurate predictor (highlighted) was the time between the first and ultimate opportunity with that customer – probably not the most useful as it could be argued as customer coming back after a reasonable period has thought about the product and decided to proceed.
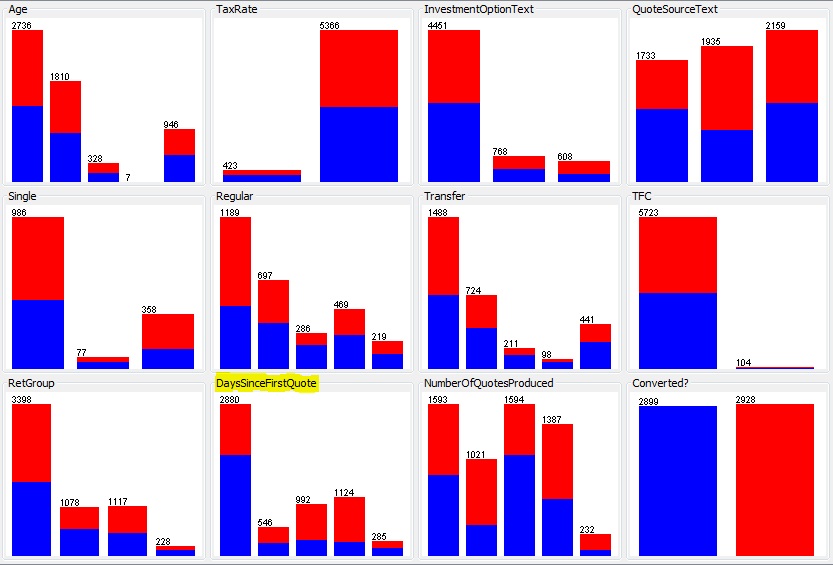
Whilst the mathematically best predictor might not be that useful in the business setting there are some other parameters that show noticeably useful predictive capabilities.
 Follow
Follow