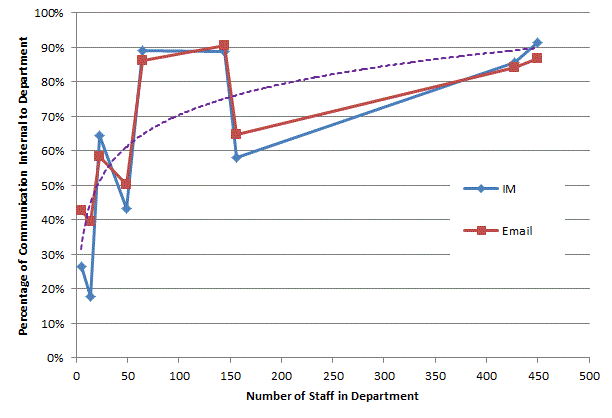
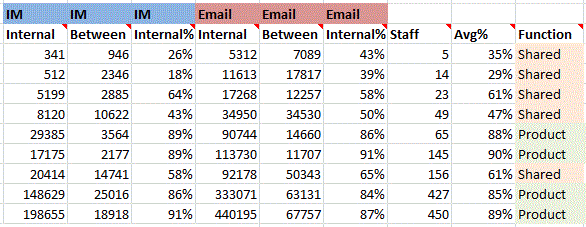
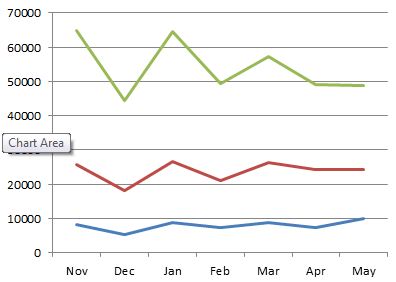
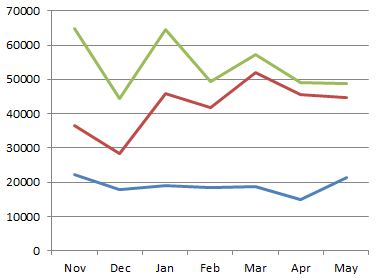
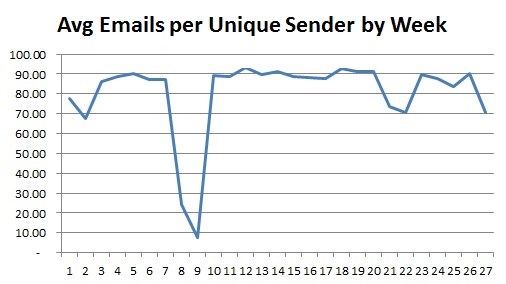
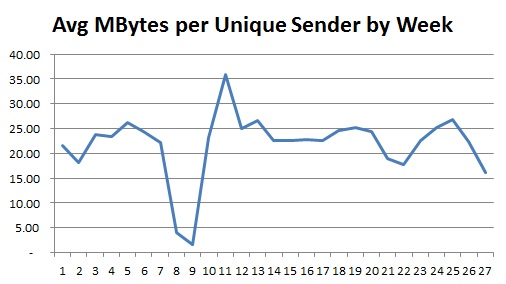
Any organisation wishing to improve will be interested in how the company functions structurally and want to investigate the causes of deviancy (weather positive or negative) from the norm. The chart below shows the percentage of communication a department generates that is internal to that department plotted against the number of people in the department. The plot is split into two: one for product-focussed departments and one for shared service departments, like HR or Accounts. As can be seen the product-focussed departments are fairly consistent, regardless of size, in that their communications are 85%-95% internal. On the other hand the departments that provide a shared service have an internal communication percentage proportional to the size of the department. Thinking about the results it does seem logical that the shared service departments are more likely to be communicating with other departments than internally but, as they grow in size, will need more internal communication to co-ordinate activities.
See my previous post for the underlying data.
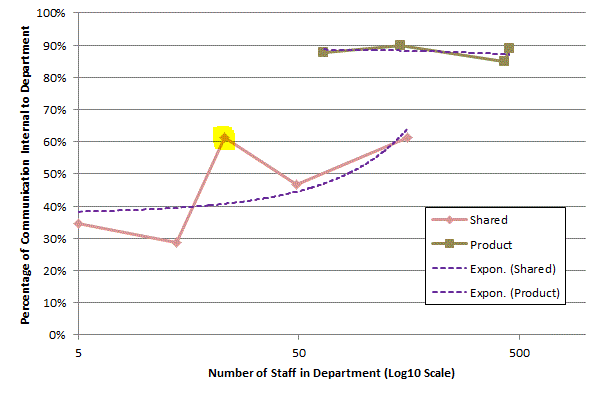
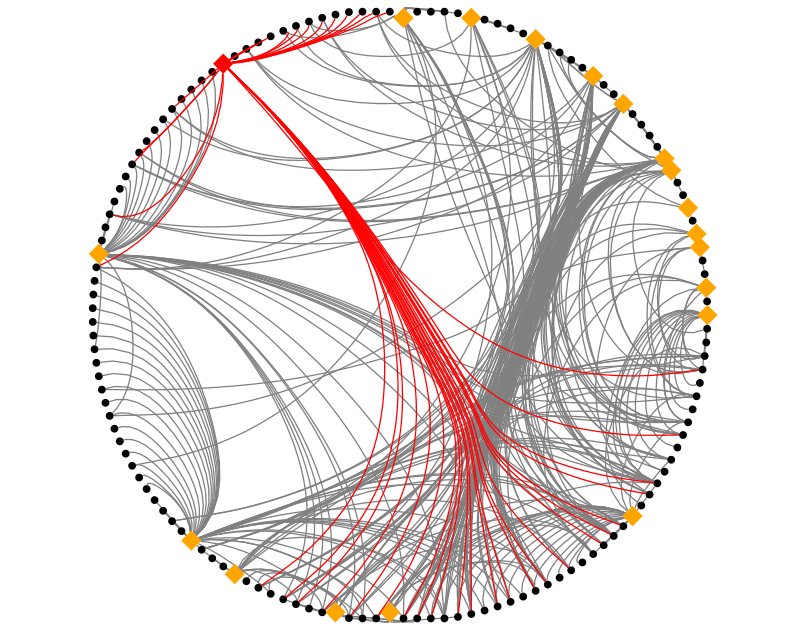
One of the shared service departments, highlighted, spends more time communicating
internally than would be expected looking at the above chart. I can’t say which
department this is but will say that I’m surprised as to which one it is.
Identifying these deviancies (which could be positive or negative depending on
how well the deviant department is performing) allow the organisation to
identify areas for further investigation in order to improve.
 Follow
Follow