I’d like to start by explaining why I referred to “NOSQL” rather than “NoSQL”: I believe that “Not Only SQL” is more accurate than “No SQL” because, of course, we can make use of both relational databases and the alternatives like document and graph. In fact this is probably just about the most miss-leading terminology of recent years because, as you will see from this article, Graph databases are structured and have query languages so they are in those regards no different to relational databases. Rant over, let me describe what I’ve learnt and hope it of help to your own journey beyond relational databases.
The reason I started working with a Graph database was to help my research into Social/Organisational Network Analysis. To get beyond the basics and start to really understand influence, and how it changes over time, I needed to be able to query the composition and strength of multiple individuals’ networks, enter the Graph Database. I won’t try explaining the concepts of a Graph Database as Wikipedia does an excellent job so I’ll jump straight in assuming you read the Wikipedia article. I chose to use Neo4j because there is some support for .NET via a couple of APIs. For the purposes of this discussion the key constructs in Neo4j are: nodes (vertices), relationships (edges) and attributes; both nodes and edges can have attributes.
The data entities I have been dealing with are: employees and items of electronic communication such as email and IM as well as other pieces of information that help identify the strength of social ties such as corporate directories, project time records and meeting room bookings. There is a whole spectrum of how these can be represented in a Graph Database but I will look at three scenarios I have either implemented, seen implemented or considered.
1) Everything is a node
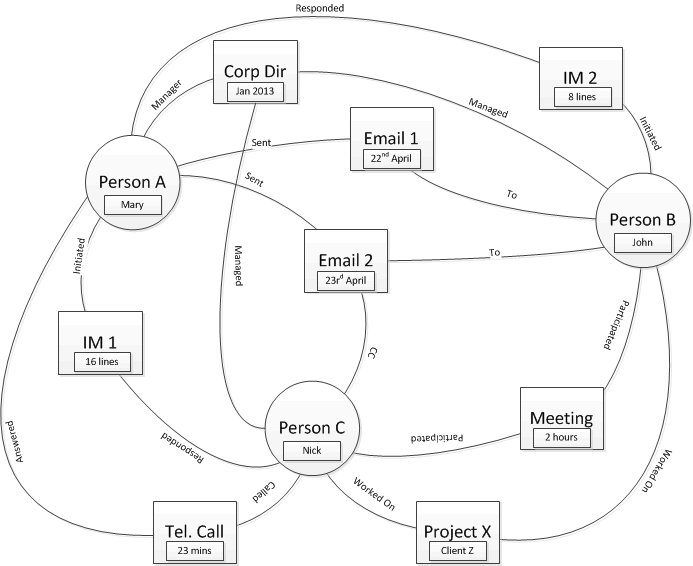
All the entities you might have previously placed in a relational database become a node, complete with all the attributes such as “meeting duration”. There are relationships between the nodes which have a type and may also have additional attributes.
Advantages: all the data in one place; you have the flexibility to query the graph in as much detail as the captured attributes allow.
Disadvantages: you could end up with a lot of nodes and relationships, the 2000 person organisation I studied produced well over a million emails per month so by the time you add in IMs and other data over a couple of years you will be in the 100 million plus range for nodes and even more for relationships potentially giving you an actual [big data] problem as opposed to the usual big [data problem]; the queries could be very complex to construct, perhaps not an issue once you have some experience but it might be better to start with something simpler.
2) Most things are a relationship
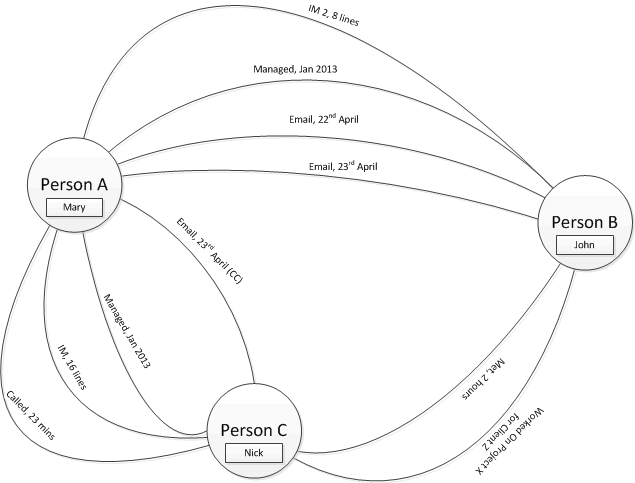
Here we keep only the ‘real world’ entities, the people, as nodes and push all the other information into relationships. For my study this would massively reduce the number of nodes but not relationships. In fact for some information, like attendance of a given meeting, the number of edges dramatically increases from n (where n is the number of people in the meeting) to n(n − 1)/2 (a complete graph).
Advantages: a lot fewer nodes (depending on the characteristics of the information involved)
Disadvantages: more edges (depending on the characteristics of the information involved); duplication of attribute information (e.g. meeting duration) in relationships; might make some queries harder or not possible.
3) Hybrid Relational-Graph
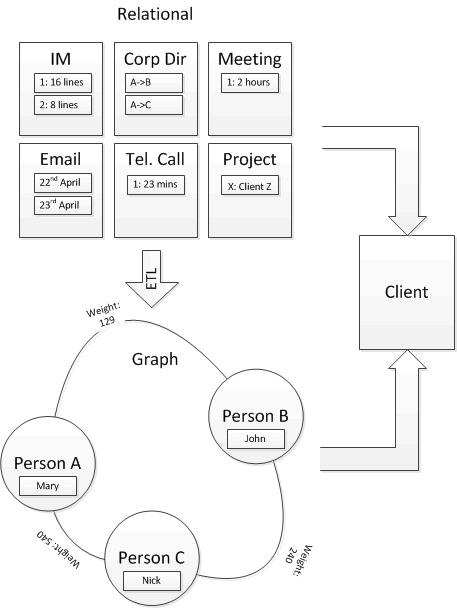
This approach effectively uses the Graph Database as a smart index to the relational data. It was ideal for my Social Network Analysis because I only needed to know the strength of relationship between the people(nodes) so was able to leverage the power of the relational database to generate these using the usual ‘group by’ clauses. I’ve shown an ETL from the Relational data to the Graph data because that’s the flow I used but they could be bi-directional or built in parallel.
Advantages: much smaller graph (depending on the characteristics of the information involved), in my data sets I’ve found 1,000 employees mean around 100,000 relationships; much simpler graph queries.
Disadvantages: Data in two places, which needs to be joined and risks synchronisation problems.
As you can guess I like the third option, mostly because it’s a gentler introduction in terms of simplicity and scale, you are less likely to write queries which attempt to return millions of paths!
At the beginning (in the rant section) I mentioned Neo4j has a query language (actually it has two). Rather than repeat myself take a look at a previous post where I describe some Cypher queries.
 Follow
Follow